What’s the Big Deal About LLMs?
LLMs are computer models that understand and create human language. But why are they so special? Imagine trying to guess the next word in a sentence your friend is saying—that’s basically what LLMs do, but they do it on a much larger scale. They can write whole essays, answer complex questions, and even translate languages!
- LLMs use patterns in language to predict the next word.
- They’ve learned from huge amounts of text—like books, websites, and research papers.
Layers of AI: How Does AI Learn?
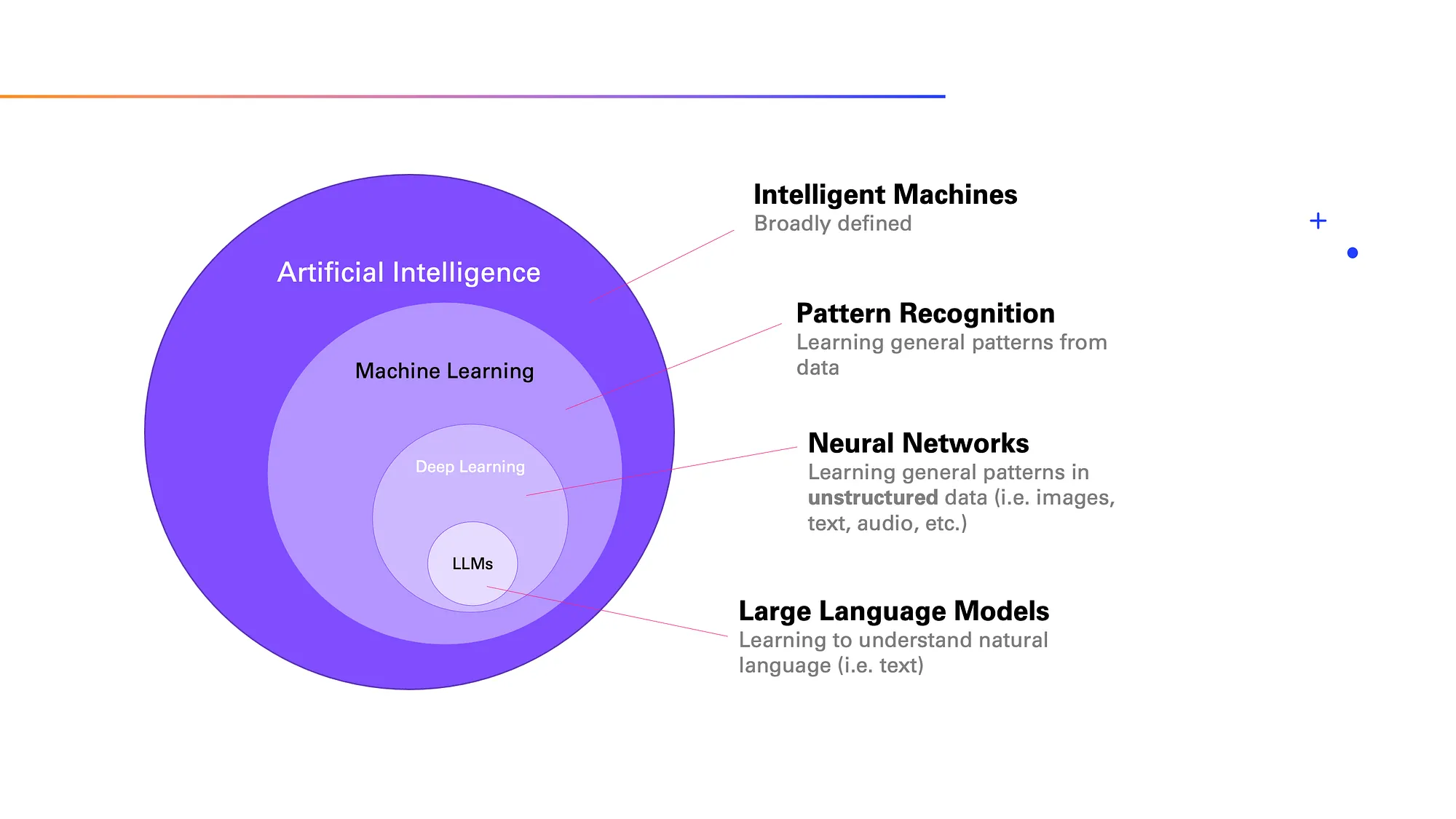
AI consists of multiple layers, each playing a unique role. Let’s break it down:
-
Artificial Intelligence (AI): This is the overarching concept of making machines capable of tasks that typically require human intelligence.
-
Machine Learning (ML): A subset of AI where machines learn from data. For instance, if you show a computer hundreds of images of cats and dogs, it will eventually learn to distinguish between the two.
-
Deep Learning: A more specialized part of ML that tackles more complex data, like images or language. This is where neural networks come in—systems loosely based on the human brain.
-
Large Language Models (LLMs): LLMs specialize in processing text and forming human-like responses, and that’s what we’ll explore in this article.
Machine Learning: A Simple Example
The purpose of Machine Learning is to find patterns in data. More specifically, it identifies relationships between inputs and outcomes.
Music Genres Example:
Imagine you want to tell the difference between two music genres: reggaeton and R&B.
- Reggaeton is known for its lively beats and danceable rhythms.
- R&B (Rhythm and Blues) is more soulful, often featuring both fast-paced and slow songs.

Suppose we have 20 songs. Each song has a tempo (how fast the song is) and an energy level. We’ve also labeled them by genre. When we plot the data, we notice that high-tempo, high-energy songs are usually reggaeton, while slower, low-energy songs are mostly R&B.
Machine Learning can automate the task of labeling genres based on these patterns, allowing us to predict the genre of new songs. This type of task is called classification, where the outcome can only be one of a fixed number of labels (like R&B or reggaeton).
The machine learns by finding a line that separates the two genres. Once it learns this, we can use the line to predict whether any new song belongs to reggaeton or R&B, based on its tempo and energy.
What if the Input is Text?
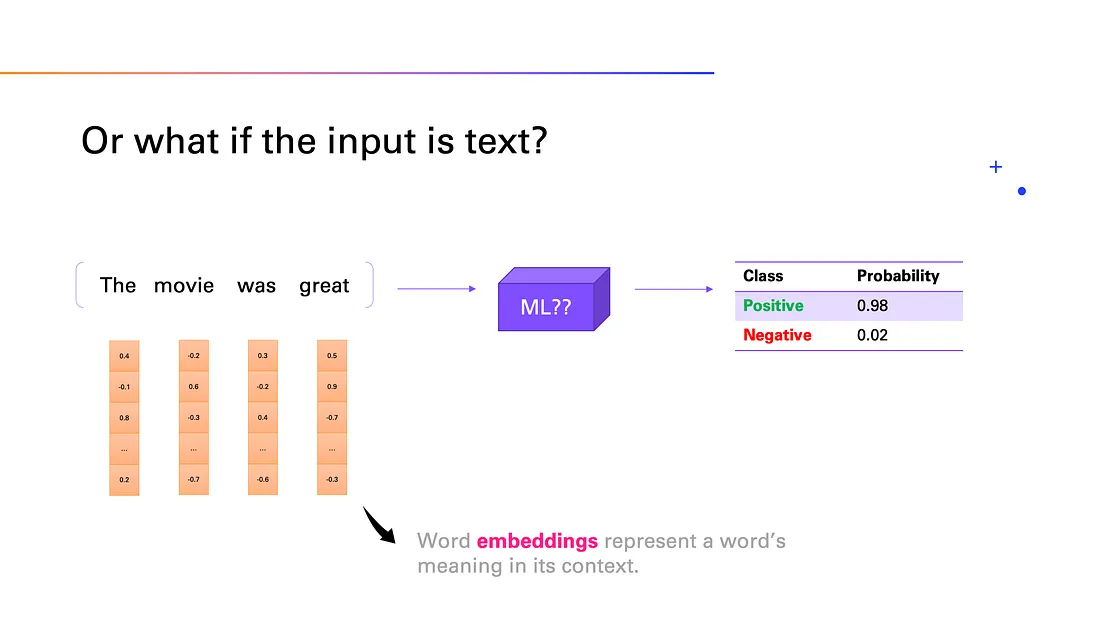
Now imagine a more complicated input: text. Let’s say we want to know whether a sentence has a positive or negative sentiment (emotion). This, too, is a classification task.
Turning words into something a computer can understand isn’t straightforward. We need to convert them into word embeddings, which are numerical representations that capture a word’s meaning. These word embeddings allow the machine to process the sentence as a sequence of numbers, which it can then use to make predictions.
Deep Learning: A Step Deeper
By now, we’ve seen that more complicated tasks (like analyzing text or images) require more powerful models. Enter Deep Learning.
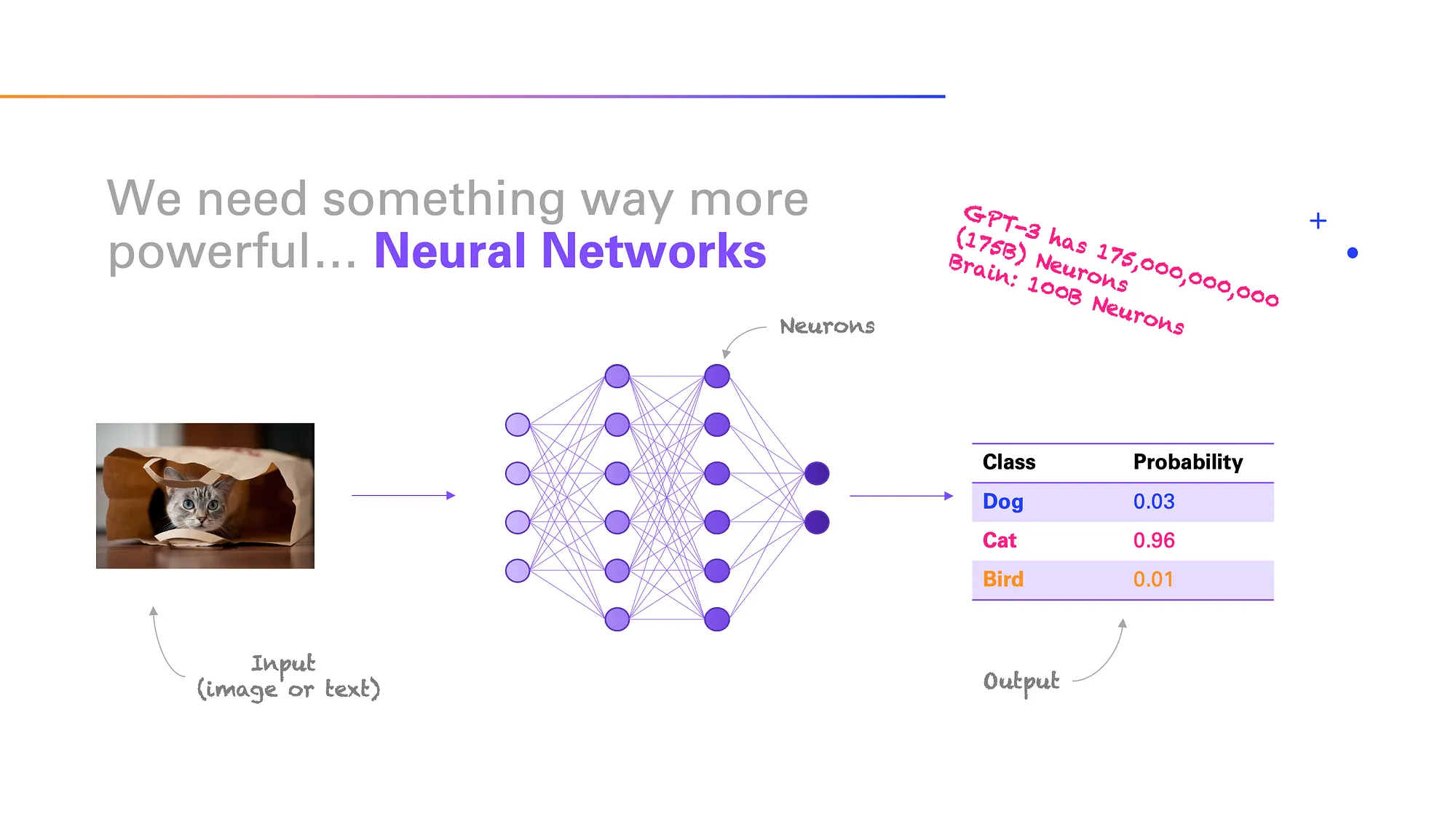
Deep Learning uses neural networks to model complex relationships at scale. These networks have many layers, each processing information and passing it along to the next. You can think of them like stacks of mathematical functions that allow the machine to learn intricate patterns.
Neural networks are often described as being inspired by the human brain, but in reality, they’re quite different. Still, their basic structure—layers of connected units called neurons—lets them model very complicated relationships.
For instance, ChatGPT is based on a neural network that contains over 176 billion parameters (neurons), allowing it to process and generate human-like responses. Compare that to the human brain, which has around 100 billion neurons.
How Do LLMs Work?
Now that we understand neural networks, we can dive into LLMs.
Let’s say you type “The cat is…” into ChatGPT. The LLM tries to predict the next word: is the cat sleeping? Is the cat running? It makes this prediction based on the patterns it has learned from millions of sentences.
What is GPT?
GPT stands for Generative Pre-trained Transformer:
- Generative: The model is trained to generate text.
- Pre-trained: The model has already been trained on vast amounts of text data.
- Transformer: This is the specific neural network architecture used.
The transformer architecture is special because it helps the model focus on the most important parts of a sentence, much like how humans pay attention to key details in a conversation.
How LLMs Learn: The 3 Steps
LLMs learn in three stages:
- Pre-Training:
- The model reads huge amounts of text and learns to predict the next word. Think of it as a giant guessing game.
- Fine-Tuning:
- After the model learns to predict words, it’s refined using real-life questions and answers. This makes the LLM more helpful when responding to users.
- Reinforcement Learning (RLHF):
- Humans step in to correct the model’s mistakes, which teaches the model to provide more accurate answers.
Pre-Training:
During this phase, the model requires a huge amount of data to learn how to predict the next word. In this process, the model not only learns grammar and sentence structure, but also gains a broad understanding of various topics, along with some additional capabilities that we’ll discuss later.
But here’s a question: What are the potential issues with this kind of pre-training? There are several, but the main concern I want to highlight is related to what the model is actually learning.
Essentially, the model becomes good at generating continuous text on a given topic, but it doesn’t excel at responding to specific instructions or questions. The issue is that it hasn’t been trained to act like a helpful assistant.
For instance, if you ask a pre-trained LLM, “What is your first name?”, it might reply with, “What is your last name?” This happens because the model has encountered similar sequences in its training data (such as empty forms) and is simply trying to complete the pattern.
It struggles with following clear instructions because this type of structured conversation—where an instruction is followed by a relevant response—was not common in the data used for training. Platforms like Quora or StackOverflow might be closer examples of that structure, but they are rare compared to the vast variety of text the model was trained on.
Fine-Tuning:
This is where instruction tuning steps in. We take the pre-trained LLM, which has learned how to predict words, and teach it something new: how to follow instructions. Essentially, we’re doing the same thing as before—training the model to predict one word at a time—but now, we’re using a more curated dataset filled with high-quality instruction-response pairs.
In this phase, the model “un-learns” its habit of simply completing text and instead evolves into an assistant that understands and responds according to user instructions. The dataset used for this fine-tuning is much smaller than what we used in pre-training, and there’s a reason for that: creating these instruction-response pairs is costly, as they require human input, unlike the massive and inexpensive self-supervised data we used earlier. This stage is referred to as supervised instruction fine-tuning for that reason.
Some LLMs, like ChatGPT, go through an additional phase called reinforcement learning from human feedback (RLHF). We won’t dive too deep into it, but this phase works similarly to instruction tuning. The goal is to further align the model’s responses with human values and preferences. Early research suggests that RLHF plays a key role in helping LLMs reach, or even exceed, human-level performance. By blending reinforcement learning with language modeling, we’re seeing tremendous potential for improving LLMs far beyond what they can currently do.
Challenges with LLMs
Despite their abilities, LLMs face several challenges:
-
Hallucinations: Sometimes, LLMs invent facts. For example, if you ask, “Who is the president of Mars?” the model might make up a name.
-
Outdated Information: LLMs are trained on past data, so they might not know the latest events. Some models, like Bing Chat, solve this by retrieving up-to-date information from the internet before answering.
Why LLMs Keep Getting Smarter
LLMs improve because:
- They are trained on more data over time.
- They use increasingly larger neural networks (some with billions of parameters).
Cool LLM Abilities
-
Zero-Shot Learning: LLMs can handle tasks they weren’t specifically trained for, like translating a sentence while using only words starting with “B.”
-
Creative Responses: Ask ChatGPT to translate “The cat sleeps in the box” using only words that start with “f,” and it might respond with “Furry friend rests in cozy quarters.”
The Future of LLMs
As LLMs continue to improve, they’ll find their way into more applications:
- Search engines will provide smarter, more relevant results.
- Digital assistants like Siri or Alexa will have more natural conversations.
- Creative tools will help generate stories, essays, and much more.
Key Takeaways
- LLMs, like ChatGPT, predict words based on the vast amounts of text they’ve learned from.
- They are trained in three stages: pre-training, fine-tuning, and reinforcement learning.
- LLMs can handle a variety of tasks, from answering questions to generating creative text.
In the end, LLMs are transforming how we interact with technology. As they evolve, they’ll continue shaping the future of AI and our everyday digital experiences.
I hope this article helps you understand what LLMs are and how they work. It’s important that everyone, not just AI experts, has a voice in how AI develops and is used to benefit society. AI is part of our future, and it’s up to all of us to guide it responsibly.
]]>This post is inspired by and references the article How Large Language Models Work from Andreas Stöffelbauer article in Meduim, and images used in the article are taken from there as well.